Policy vs Plan
지난 포스팅에서 다루었던 Markov Decision Processes에 대해 복습해보자.
MDP란 Markov property 속성을 갖는 Agent의 행동에 대한 Mathematical framework으로
Markov property란, 현재 상태에서의 행동은, 여태까지 어떻게 현재 상태에 도달했는지에 무관하게 오직 현재 상태에만 의존한다.
였다. 이러한 Markov property를 agent에게 부여함으로써, 더 불확실한 환경요소에 대해 모델링 할 수 있게 되었다.
그럼 MDP를 포함하는 Bellman equation은
$$ V(s) = \underset{a}{max} (R(s,a)+\gamma V(s^{\prime})) $$
로 표현 할 수 있다.
Plan
우리는 Plan에 대해서 다뤄본 경험이 있다.
각 State의 Value를 계산하여, 각각의 state에서 agent가 어떤 action을 취해주어야 하는가
에 대한 일종의 지도 같은 것이었는데,

다음 그림의 예시가 기억이 안난다면 지난 포스팅 Plan 를 참고하길 바란다.
Policy
하지만, 우리는 이제 plan을 사용하지 않을 것이다.
Markov Decision Process 에서 눈치를 챗을 수 도있지만, 임의성을 부여한다면,
우리의 이상적인 계획대로 실행되지 않을 경우도 있을 수도 있기 때문이다.
계획은 단지 우리가 다음 action을 그리고 다음 환경을 정확히 이해하고 있을 때만 가능하다.
여기서 다음 그림을 봐보자
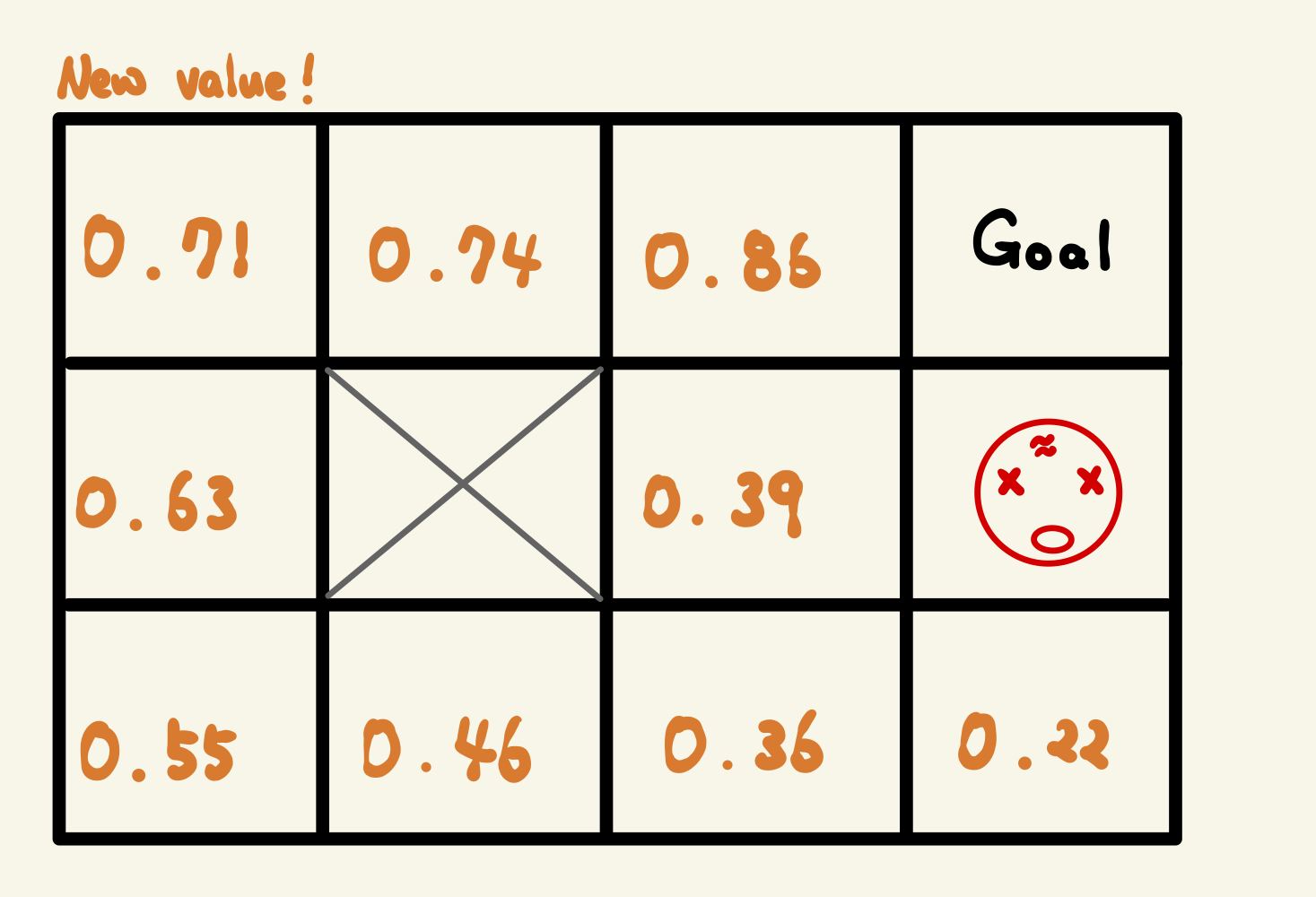
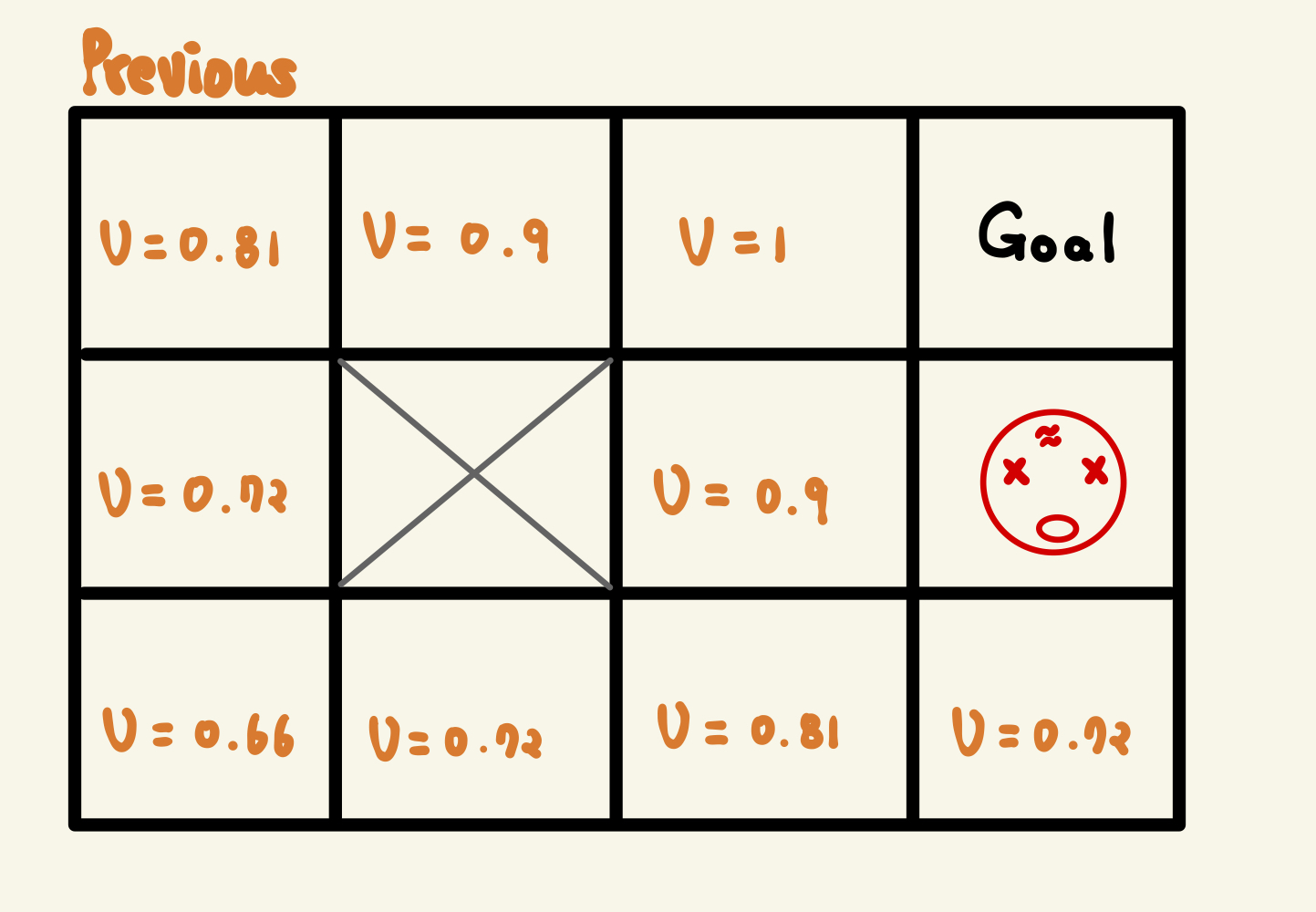
이전 Value와 비교하면 Value가 달라져 있다.
(참고: 이전 value)
왜 달려져있을까 ? 어떤 근거로 달라져 있을까 ?
V =1 의 state를 예를 들어보자
원래 V = 1 였던 state에서는 그냥 오른쪽으로만 가면 됐었다.
하지만, 임의성을 부여한다면 그렇지 않다.
왜냐면 오른쪽으로 가는 것이 우리의 목표여도 임의적인 확률로
오른쪽이 아니라
윗 방향, 왼쪽 방향, 아랫 방향으로 action을 취할 확률이 존재하기 때문이다.
실제로 귀납적으로 MDP가 포함된 Bellman equation을 풀면 value값들을 계산할 수 있지만,
analytic하게 풀기는 어렵다.
하지만, AI는 여기를 다 탐색해 보면서 계산을 할 수가 있다.
실제 저런 값이 나오는지는 $ \gamma $ 나 P 에 따라 달라질 수 있지만,
중요한 점은
1. 가치가 변했다.
2. 변한 가치가 대부분 이전보다 작아지는 경향을 보인다.
이다.
또한 흥미로운 점 하는 V = 0.9 에서 0.39로 확 낮아진 곳이 있는데, 왜 그럴까?
답은 옆에 R = -1로 갈 수 있는 확률이 있어서 이다.
따라서 이전과 다르게 Agent는 불구동이 옆으로 지나가는 것보다,
X 블록을 끼고 돌아가는 편을 택할 것이다.

이를 화살표로 바꿔보자

주황색은 뭐냐 ?!
AI는 인간의 상식 밖의 아이디어를 제공한다.
"왜 ? 위로가야해 ! 그러면 낮은 확률이지만 불구덩이에 닿을 텐데" 라고 생각하는 것이다.
그럼 왜 벽으로 박치기를 해야하냐면
벽으로 박치기를 하는 선택지는 높은 확률로 벽에 박아서 다시 되돌아오겠지만,
낮은 확률로 위,아래로 갈 선택지가 있기 때문이다.
따라서 벽에 부딪이는 방법으로 R = -1 의 선택지를 지울 수가 있다.
결국 정책이란, AI 가 혼자 설계한 바람직한 경로이며,
해당 화살표와 다르게 움직일 가능성은 충분히 존재한다.
'Reinforcement learning 기초' 카테고리의 다른 글
| [Reinforcement Learning] Q-learning Intuition (0) | 2023.04.15 |
|---|---|
| [Reinforcement Learning] Living Penalty (0) | 2023.04.15 |
| [Reinforcement Learning] Markov Decision Process (0) | 2023.04.11 |
| [Reinforcement Learning] Plan에 대해 (0) | 2023.04.11 |
| [Reinforcement Learning] Bellman Equation (0) | 2023.04.10 |




댓글